Overall Architecture
Architecture Diagram
As a distributed database, DingoDB is designed to consist of multiple components. These components communicate with each other and form a complete DingoDB system. The architecture is as follows:
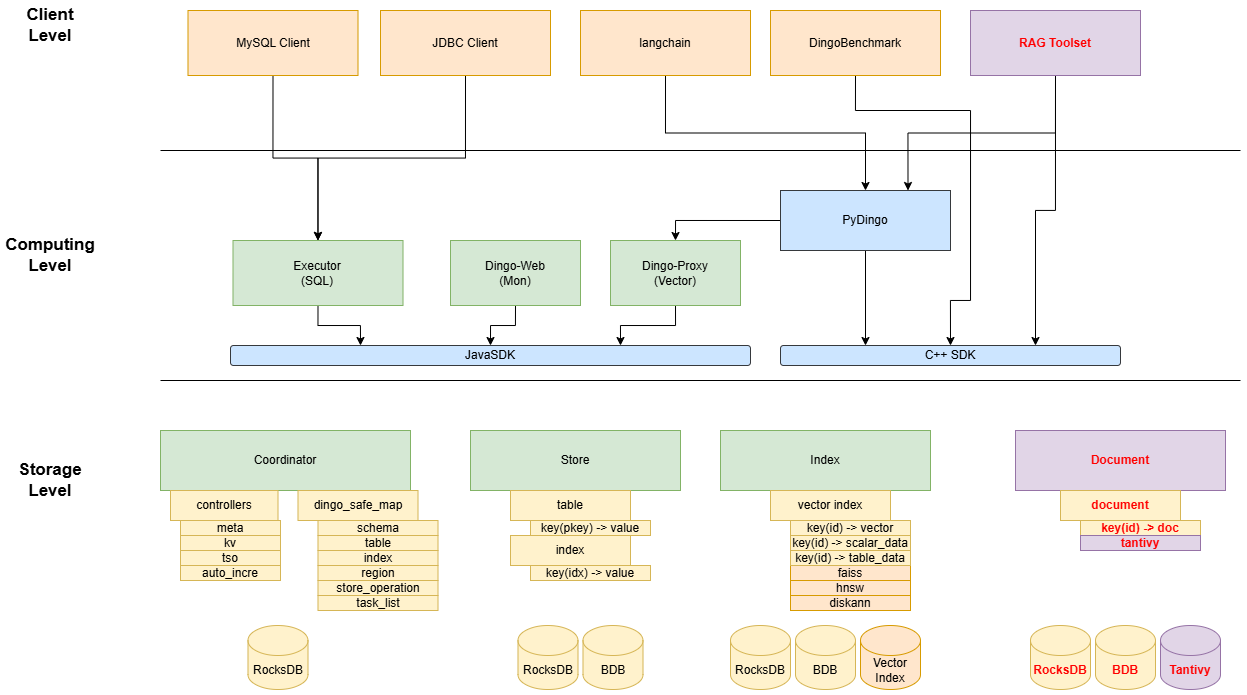
Component List
1. Computer Layer
The computer layer is a stateless SQL layer that exposes the connection endpoint of DingoDB using JDBC protocol to the outside. The Coordinator receives SQL requests, performs SQL parsing and optimization, and ultimately generates a distributed execution plan. It is horizontally scalable and provides the unified interface to the outside through the load balancing components such as Linux Virtual Server (LVS), HAProxy, or F5. The computer layer does not store data and is only for computing and SQL analyzing, transmitting actual data read requests to the storage layer.
Executor
Executor acts as a SQL Server, parsing and responding to SQL requests and other management requests from the Client side, realizing the JDBC protocol; performs Job management, realizing distributed execution of Tasks; calls the lower Meta, Store APIs through the SDK to realize database functions.
Dingo Proxy
Serves as a bridging layer for vector operations and provides HTTP/gRPC interfaces for the Python SDK.
2. Storage Layer
The storage layer supports row and column storage mode. Row mode supports high-frequency insert and update scenarios; Column mode supports interactive analysis and multi-dimensional aggregation analysis in real-time and so on.
Coordinator
Coordinator is responsible for metadata management, recording the table structure and deciding the distribution of data in store nodes; scheduling management, responsible for allocating and managing data slices; monitoring the status of the cluster by receiving heartbeats from store nodes; in addition to providing global services.
Store
In row storage mode, the store is a distributed key-value storage engine embedded in Executor. The region is the basic unit to store and replicate data. Each Region stores the data for a particular Key Range which is a left-cleosed and right-open interval from StartKey to EndKey. Multiple Regions exist in each Executor node. Executor APIs provide native support to operator data, such as get, put, scan, iterator, and so on.
3. Clients
Outside the DingoDB cluster, you can use clients to connect to DingoDB to do analysis. The client has Jdbc-driver and Sqlline mode.
JDBC Driver
JDBC stands for Java Database Connectivity, which is a standard Java API for database-independent connectivity between the Java programming language and a wide range of databases. DingoDB is a flexible distributed database, you can use any database tool embedded dingo-thin-client to connect to DingoDB such as the universal database tool dbeaver .
Sqlline
SQLLine is a pure-Java console based utility for connecting to DingoDB and executing SQL commands,you can use it like sqlplus for Oracle,mysql for MySQL. It is implemented with the open source project sqlline.